Scaling Without Slowing Delivery
Maximize the value you ship this week and you’ll minimize the value you ship this year.
This is a dynamic that can happen in growth-stage companies when they continue using startup-stage product engineering approaches long after their effectiveness declines.
Focusing all development efforts on a feature roadmap ordered by urgency makes sense for startups – which need to quickly find PMF, have small user bases and teams, and are developing their codebases from scratch.
But continuing this approach in a scaleup slows delivery rates over time and raises delivery unpredictability.
This in turn slows company growth and makes it vulnerable to competition, even as it appears on the surface to be moving as fast as possible.
Scaleups instead need to adopt new product engineering practices suited to their stage if they wish to sustain delivery speed as they grow.
It isn’t enough to professionalize the business with additional layers of management, team reorganizations, and new departments.
Engineering strategy also needs to be realigned to the realities of a post-PMF company with a large existing codebase forged on the fly during a chaotic PMF hunt.
AI amplifies this. Using AI the way startups do will produce lackluster results and squander opportunities that AI creates elsewhere (which I discuss further here).
In short, you need to engineer your engineering for maximum delivery speed and reliability, using approaches that match the current stage of your product and company.
Maximizing for growth
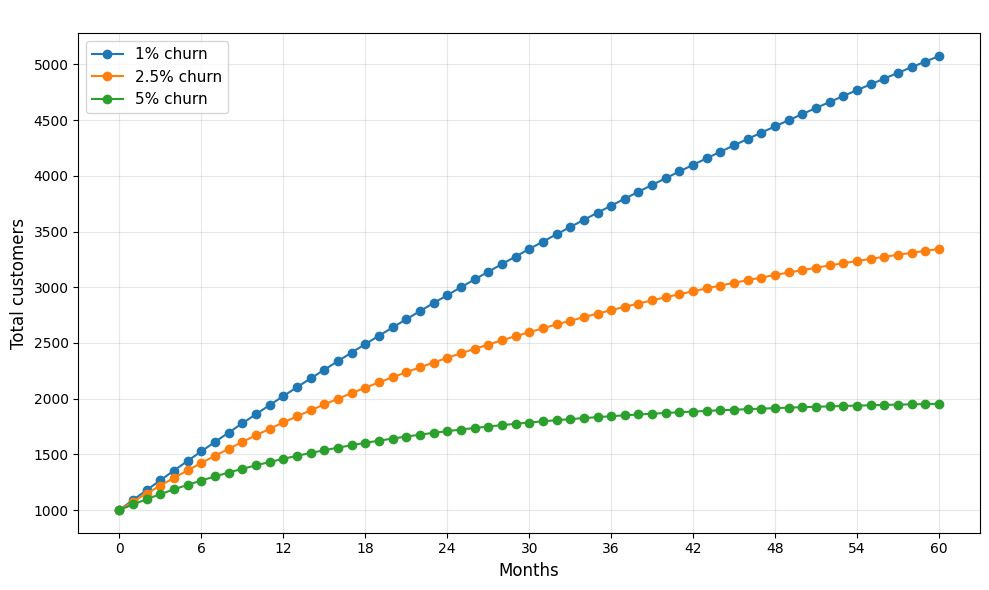
Delivery speed and reliability affect the two main levers of a scaleup’s growth rate: customer acquisition and churn.
New features improve sales opportunities, and customers who get the features they want quickly – and who aren’t frustrated by bugs and production incidents – will be happy customers who buy more and recommend the product to others.
Customers who are frustrated by the product will instead want to rid themselves of it. Churn is insidious because it’s the fraction of customers who leave over time. Eventually, the company reaches a growth ceiling where customers leave as quickly as they can be acquired – not a growth trajectory investors like to see.
AI encourages them too, allowing them to quickly and easily build something themselves.
Yes, they’d still have to develop and maintain it, and it’s still easier to use something off the shelf that’s maintained by someone else.
But that equation shifts when a vendor takes months to investigate bugs and simple features get forecast for delivery next year, or the product regularly suffers production incidents. Self-build means I can self-fix and self-extend.
This is why it’s so important for scaleups to sustain their development pace and reliability.
It keeps your customers around rather than plotting to replace your product in-house.
So what differentiates the scaleups that succeed at this from the ones that don’t?
It’s understanding accumulated complexity.
A scaleup's accumulated complexity – in its codebase, processes, and team topologies – sets the pace for every subsequent feature or bug fix. It also determines the frequency of emergent behavior, a primary cause of bugs and production incidents.
A large portion of this complexity is non-essential, existing as a byproduct of urgency and accumulated changes in direction over the company’s lifetime.
And the kicker is this: reducing this accumulated complexity is never urgent, and therefore never gets done unless company leadership integrates it into their strategy.
The curse of urgency is that it slows down the roadmap despite presenting a veneer of “full steam ahead".
Accumulated complexity is worse than you think
Accumulated complexity causes a superlinear decline in development throughput.
Software development is accretive, and each new change needs to fit perfectly within the web of existing logical relationships in the codebase.
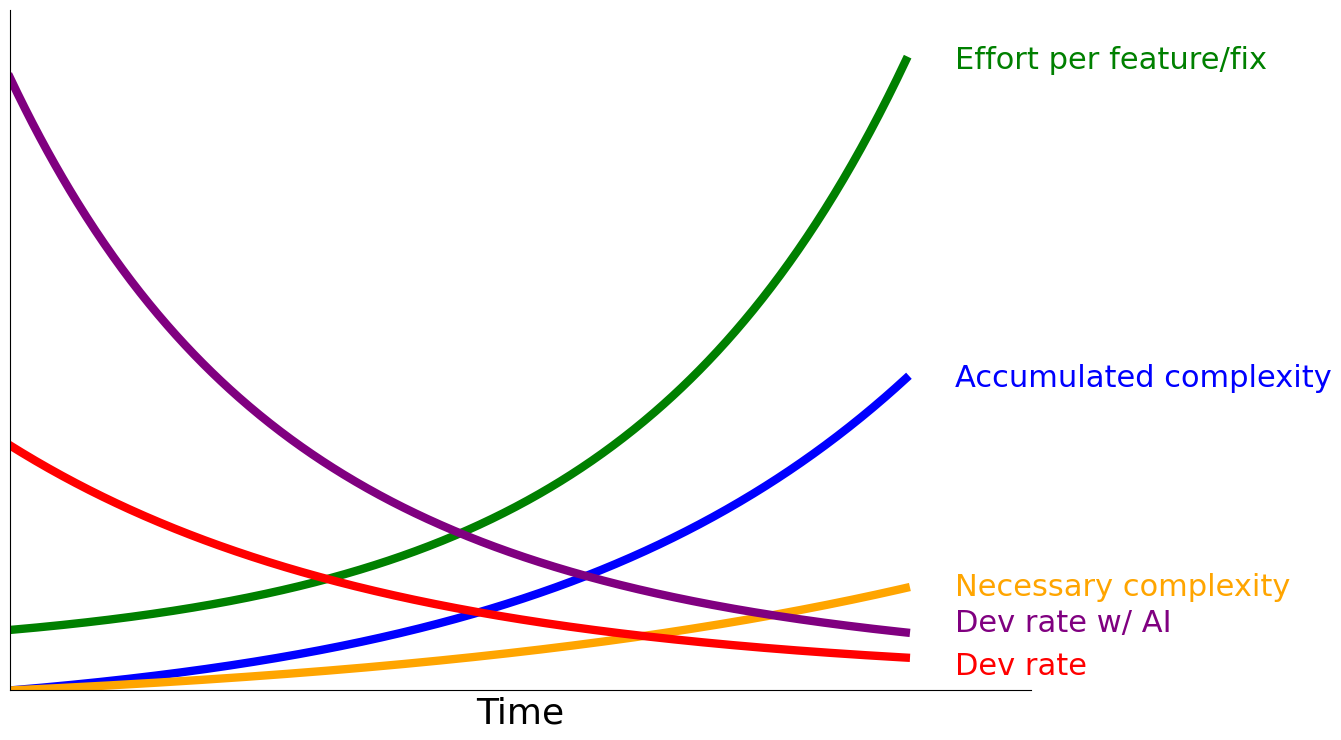
This cannot be countered by headcount growth – even if the budget is available – because headcount increases productivity sublinearly.
AI doesn’t counter it either. LLMs are prediction machines. Higher accumulated complexity reduces the likelihood of them guessing the correct next code change.
This leads to longer agent running times which either fail to converge on a solution, produce incorrect changes, or increase emergent behaviour. This in turn increases AI costs.
This combines to create a significant challenge: a scaleup naturally ships slower as time passes due to this accumulated complexity, its competitors (startups and self-builders) start afresh and so get to ship at full speed, and urgency-prioritizing organizational tendencies prevent complexity reduction.
How can a scaleup escape this trap?
Operationalizing engineering
The solution is operational measures.
Leadership needs to treat engineering as a flawed value-producing machine in need of constant improvement.
This requires dedicated resources focused on continuously improving that machine.
This resourcing can take many forms. But the most important consideration is this: it must never compete for prioritization with features and bugs.
It must always be separate, or it will be perpetually blocked by relentless urgency-based deprioritization.
Through these dedicated resources, the engineering machine can steadily approach the ideal scenario: running like clockwork.
Cases in point
The guiding principle for finding high-impact improvements is the Pareto principle – a.k.a. the “80/20 rule” – in which engineers target friction points. These are areas where accumulated complexity is showing up as clear bottlenecks and productivity losses.
The kinds of friction points are innumerable, but here are a few examples from my own career.
Manual processes
The company published changelogs on its website for each of its software releases.
The source of those changelogs was a custom field on its Jira tickets, populated by the developers.
The process for moving the changelogs from the Jira tickets to the website was entirely copy-paste. For each release, developers would manually add changelog entries into giant JSON files which were then parsed by the website, which included manually typing out the date and version number.
A non-engineer had raised this as a clear automation target several times over the years, but no action had been taken.
Given the number of engineers and the volume of changelogs, this amounted to over six developer-months of lost time per year.
Unsurprisingly, it was error prone too.
Not only was this process straightforward to automate using scripts, but doing so helped increase my understanding of connected systems, which inspired further simplification of adjacent processes.
However, the script did not gain widespread uptake. The time savings were only realized once the process was removed from general responsibility and transferred to a single IC tasked with operating it on behalf of all engineering.
Companies often don’t realize the scale of the payoff from automating manual processes. Much of this work involves fresh builds like scripts – and AI can blast through that work like a hot knife through butter.
The most recent automation project I worked on – a runtime upgrade automation script – took one week to complete using Opus 4.5, for an ongoing savings payoff of at least six developer-months a year.
That’s an ROI of over 2000%. Think of all the extra features you can develop with that.
Cross-department friction
The company had separate departments for engineering and operations, which reported to different VPs in different time zones.
This is a well-known recipe for ongoing contention, known about since the days of engineers physically carrying floppy disks across an office to operations.
However, there were several structural and commercial reasons why moving to a DevOps structure was not yet feasible.
Given the size and complexity of the company’s codebase and systems, there were ongoing points of contention between engineering and operations. Operations expressed constant frustration with engineering, while engineers felt in the dark about how to interact with them without upsetting them.
The losses from this situation were hard to quantify, but were felt constantly. The inevitable production incidents it caused led to blowout meetings that pulled in multiple VPs, and those meetings did not result in lasting remedies. Handoffs would routinely result in long Slack threads where engineering and operations would discuss or debate how they should be handled.
My estimate was ongoing losses of at least 5% of the total engineering and operations bandwidth, in addition to its impact on customer trust due to the increased rate of production incidents.
The solution was a working agreement between those departments.
All up, it took roughly 30 hours to complete: interviews with operations and engineers, drafting and revising the text, and having discussions with other engineering managers until we had something we were all happy with.
But what struck me most about the process was how little contention there was. There was almost no disagreement on fair expectations from each other – the problem was those expectations had never been decided and written down.
The result was a precipitous drop in conflicts, saving at least 12 developer-months of lost time per year, an improved working environment, reduced firefighting meetings for VPs, and increased organizational scalability.
Again, many scaleups do not realize the magnitude of the ROI from this work. We are not talking about single-digit IRRs – we’re talking payoffs that are frequently 10x or more.
Painful onboarding
The company’s onboarding process when a developer joined a project went something like this.
The new developer would be told to “set up project X” on their machine.
The project’s documentation had not been updated in years, and what documentation was there was wrong.
The new developer would spend a week trying to reverse engineer how to get it running. They would frequently interrupt other senior developers, who would then share information present only in their own heads (often uttering the dismissive word “just” as part of their directions), or would themselves spend an hour trying to solve the current sticking point.
The solution was not complex. It was merely deciding to fix the situation.
For the last project I worked on at that company, I was able to reduce the entire onboarding process to executing ./run.sh. (In theory the onboarding could have been reduced further to “zero-step” onboarding, where new hires are handed a machine with projects already installed and running.)
This was not a big lift either, totaling roughly 15 hours (pre-AI) to complete. But instead of it being resourced, it was left to the random chance of an engineer deciding to improve it in secret.
That represented a saving of approximately one week of development time per onboarding per project. With roughly 50 onboardings per year, that’s equivalent to gaining one free developer.
This initiative did not spread to other projects; other things were more urgent, as they always will be.
Overengineered legacy project
The company had a microservice architecture. One of the services, which was heavily used by others, had been developed in an exceptionally complex way, over ten years ago.
It took a senior engineer over a week to trace how a request to the service actually reached the business logic, with call stacks so deep and convoluted that he resorted to creating detailed diagrams to understand what was going on.
And that business logic wasn’t even within the service – it was within a library maintained separately.
The build chain for the service took over 15 minutes to complete, fans howling all the way. We found this to be impressive given that the service was not even written in a compiled language.
The service had singlehandedly driven developers to the point of burnout. No developers remained at the company who understood its inner workings, because since the original developers left many years ago, other developers had done their utmost to stay away from it.
A new app was going to require significant changes to this service. Given its condition, I determined that was not economically feasible, and that the service should be considered in maintenance mode.
Instead, I wrote a partial replacement for it from scratch, and routed the new app’s requests to that instead. This replacement took less than two weeks to complete (pre-AI), and consisted of one small JavaScript file.
As a side effect, this allowed other developers working on the library to avoid touching the old service and its slow builds, saving them hours a day.
Countless hours could have been saved had this decision been made earlier.
Installing the continuous improvement apparatus
Across multiple such initiatives, the pattern I’ve noticed is that most are not difficult to implement. Rather, the challenge is in sustainably resourcing and managing them.
At the company level, this means installing an apparatus that continuously executes improvements.
This apparatus has three parts:
- The sensors, which detect friction points;
- The controller, which decides which changes should be made next; and
- The actuators, which implement those changes.
The apparatus must be resourced with a mandate from leadership. This means a fixed allocation of resources dedicated exclusively to improving development throughput and reliability.
This must be a quota rather than a budget. For example, a minimum of 15% of engineering capacity each quarter.
Sensors
Friction points should initially be surfaced by asking developers, typically through an anonymous Developer Experience (DevEx) survey. This quickly reveals high-impact opportunities.
This should be supplemented by bird’s-eye-view investigations, such as value stream mapping. Some friction points are dispersed enough that no individual developer will spot them from where they’re standing.
Quantitative metrics should also be used, such as DORA metrics, tool telemetry, onboarding duration, build times, and developer satisfaction scores.
Another important source is root cause analysis (RCA) of incidents. This doesn’t just apply to production incidents, but to pre-production problems too. An RCA conducted on minor internal incidents can often spot a source of problems before they lead to a production incident.
Other sources include analyzing retrospective meetings (which is why their minutes should be recorded), reviewing long Slack threads, and inspecting CI/CD failure patterns.
Controller
With friction points identified, they need to be prioritized – fastest & highest impact initiatives to the top of the list.
Since we’re maximizing for fast and reliable delivery, “impact” must trace to those two parameters.
For speed, the metric is return on development time. In most cases, the value of an improvement can be approximated as a perpetuity by dividing the recurring time savings by the time required to implement it.
This can further be expressed as a payback period – “it’ll pay for itself in 6 months”, and subsequent recurring savings – “it’ll free up four dev-months per year of lost capacity”.
This means the total features developed over that time period are the same whether or not you diverted time away from feature work to complete the project.
It also means that if you don’t complete the project, you’ll continue to lose the features that would’ve come from that freed-up development capacity.
This narrative is important to help counter urgency bias – urgency is reducing feature output, not increasing it.
For reliability, the metric is reduction in delivery unpredictability – fewer production incidents and bug reports, missed forecasts, and realignment meetings.
This is harder to quantify. But as McNamara’s fallacy teaches us, measurability should not dominate decision making.
For example, a team may identify a specific component as causing a disproportionate number of urgent bug reports, which are regularly impacting the development forecasts for their roadmap. Based on this ongoing impact, they decide it should be raised to the top of the list, notwithstanding the lack of a numeric ROI.
Actuators
The friction points then need to be cleared one by one.
This is the most challenging part of the apparatus. Even with poorly identified or incorrectly prioritized friction points, great results can still be achieved if they are solved rapidly.
But with weak execution even the best plans fail, and there are a multitude of ways for execution to go wrong – causing loss of faith and collapse of the initiative.
This risk can be mitigated with good Agile fundamentals. Just because these are internal projects does not mean they should be managed more casually.
This means that someone needs to play the role of the Product Owner, ensuring the work is managed by the same principles as if it were being shipped to paying customers.
This includes being subject to the same ceremonies, task management, and quality control as other work.
As for who should carry out the work, there are several schools of thought, and the best approach will differ by organization.
Some prefer to push responsibility for the work into platform teams. The platform team plays an important role, but this is insufficient as the sole mechanism.
Firstly, not all improvements require building platform-level tools. Some of the best improvements just require negotiating agreements with other departments. Others involve changes to software and systems that the platform team knows little about.
It also creates an “internal product” situation for a team of engineers that lacks a professional customer service function. This can stoke an us-vs-them dynamic, replacing one problem with another.
Others may prefer to create a dedicated DevEx team. This is much better. It is harder for resources to be diverted away from a team that serves only that purpose. But it’s only justifiable for larger engineering headcounts than many scaleups have. Experienced engineers may also be wary of joining the kind of team that can be easily cut during downturns.
Others leave it to whim: occasionally a lone developer will come up with a tool that automates a personal botherance and shares it with others. This fails because the solution seldom gets used by others. It usually solves a local problem rather than a broader one, and lacks the change management required for wider adoption.
The approach I prefer is cross-team taskforces plus a program leader.
Engineers are very capable of building and maintaining the tools that they use. They are also far more likely to use tools that they or their own team has played a role in developing, because it naturally embeds internal champions and tool experts into those teams.
And since they’re closest to the work, they have the clearest and most up to date knowledge of what tools and process improvements are actually needed.
They also can’t complain about tools and processes that they’re empowered to fix.
So I believe the best results come from having several teams temporarily contribute engineers to a shared initiative that improves things for them all.
The Pareto principle applies here as well: most developers are not particularly interested in this kind of work. It’s therefore important to select those passionate about it, who won’t view it as a chore imposed on them.
The program leader should be someone with a strong track record of passion and proficiency in this kind of work. Their role is overseeing the apparatus, ensuring it keeps delivering improvements, and that it continues to improve itself.
Detailed example with calculations
The following is a hypothetical example derived from a personal experience.
A software company uses long-term support (LTS) versioning for its product, allowing clients to remain on stable versions of the software.
However, bug fixes are usually backported to all supported versions. Teams have been applying these patches manually.
These backports are often extensive. The company uses a polyrepo version control topology, and many bug fixes require changes across multiple repositories, some of which are used as submodules by others. This effort is multiplied by the number of LTS versions, which averages six at any point in time.
An engineer has identified this as an automation opportunity and proposes an initiative to build a tool that can execute backports automatically, handing over to the developer only in edge cases.
To justify the initiative, ROI is calculated.
Engineering completes 40 bug tickets per two-week sprint.
From GitHub PR merge records, it is determined that the backporting work takes around one hour per bug on average.
It is estimated that if the tool is developed successfully, it will automate 90% of this work.
We then estimate the recurring savings:
- 20 bug tickets per week × 1 hour × 90% = 18 hours per week saved in perpetuity
The engineer then breaks down the work involved, and based on prior experience leveraging AI, estimates it will take 45 hours to build the tool and thereafter cost 2 hours per week to maintain.
It is further estimated that the change management required to bring the tool into regular use across all teams will cost a further 85 hours, for a total upfront cost of 130 hours.
ROI is then:
- Annual savings: (18 - 2) × 52 = 832 hours
- Upfront cost: 130 hours
- Annual ROI = 832 / 130 = 640%
- Payback period = 130 / 16 = 8.125 weeks
This means that the project would pay for itself after about 8 weeks and deliver around 20 developer-weeks of capacity savings per year.
This is identified as the highest-impact efficiency initiative currently known. It also clears the 100% hurdle rate set by the executive team.
A senior engineer from one team is selected to lead it, with an engineer from another team assisting and one engineer from every other team participating in drafting the acceptance criteria.
Once the initial version is complete, those engineers test it within their teams. Feedback is gathered and revisions are made until it is ready for general use.
The task force creates documentation and demo videos to go along with the tool, presents it in appropriate channels, and continues to check in with teams about it over the coming months.
They also track usage of the tool, survey developers about it, and follow up with managers as needed until critical mass has been attained and it has become the default way to perform backporting.
Conclusion
The example returns I have used – involving hundreds or thousands of percent – are not an exaggeration.
AI has significantly shortened the time it takes to complete these initiatives, and scaleups have larger engineering organizations over which the gains can be multiplied.
For a scaleup that has yet to implement a concerted program of continuous improvement, these opportunities are abundant.
The challenge isn’t in finding these opportunities; it's in installing the ability to act on them.